その3 ボストンの住宅価格を多項式回帰で予測してみた
どうもhinomarucです。
今回は多項式回帰を試す
多項式回帰とは?
統計学における多項式回帰(たこうしきかいき、英: polynomial regression)とは、従属変数 y を独立変数 x の n 次多項式でモデル化する回帰分析の一手法である。多項式回帰は、従属変数と独立変数とが非線形的な関係で表現されるような場合に適しており、例えば神経組織の成長[1]、湖底堆積物中の炭素同位体の分布[2]、感染症の拡大[3]の記述に用いられてきた。多項式回帰ではデータに非線形なモデルを当てはめるが、推定理論(英語版)においては線形の問題に分類される。というのも、推定される関数が未知母数の1次式だからである。この意味で、多項式回帰は重回帰分析の特別な場合とみなされる。 Reference: https://ja.wikipedia.org/wiki/%E5%A4%9A%E9%A0%85%E5%BC%8F%E5%9B%9E%E5%B8%B0
今まで読んできた本には出てこなかったのか、 読み飛ばしていたのか今回多項式回帰の存在の初めて知りました。
回帰についてもう少し勉強する必要がありますね。 図書館で回帰分析についての本を借りることにします。
Checking Boston housing prices corrected dataset 3
パッケージのインポート
import packages
import seaborn as sns import statsmodels.api as sm import pandas as pd
データの読み込み
reading data
df = pd.read_csv("http://lib.stat.cmu.edu/datasets/boston_corrected.txt",skiprows=9,sep="\t")
※ 22年2月1日更新: UnicodeDecodeErrorが発生する方はencoding='Windows-1252'を追加してください。 詳細は下記新ブログをご参照ください。
list(df.columns)
Out[0]
['OBS.',
'TOWN',
'TOWN#',
'TRACT',
'LON',
'LAT',
'MEDV',
'CMEDV',
'CRIM',
'ZN',
'INDUS',
'CHAS',
'NOX',
'RM',
'AGE',
'DIS',
'RAD',
'TAX',
'PTRATIO',
'B',
'LSTAT']
サンプリング (訓練データ、テストデータ分割)
# 訓練データとテストデータに分割する。 # 本当は町ごとにサンプリングした方がいいと思うが、TODOにしておく。 from sklearn.model_selection import train_test_split # TODO:層別サンプリング train, test = train_test_split(df, test_size=0.20, stratify=df["町区分"], random_state=100) train, test = train_test_split(df, test_size=0.20,random_state=100)
訓練データ、テストデータ作成
# 変数の組み合わせは前回の重回帰分析と同じ X_train = train[["RM","LSTAT","PTRATIO","B"]] Y_train = train["CMEDV"] X_test = test[["RM","LSTAT","PTRATIO","B"]] Y_test = test["CMEDV"]
#import polynomial package from sklearn.preprocessing import PolynomialFeatures #n=2で試してみます。 poly_reg = PolynomialFeatures(degree = 2) X_train_poly = poly_reg.fit_transform(X_train) X_test_poly = poly_reg.fit_transform(X_test)
X_test_poly
Out[0]
array([[1.00000000e+00, 7.27400000e+00, 6.62000000e+00, ...,
1.58760000e+02, 4.94172000e+03, 1.53820840e+05],
[1.00000000e+00, 6.55200000e+00, 3.76000000e+00, ...,
3.02760000e+02, 6.61791600e+03, 1.44658516e+05],
[1.00000000e+00, 6.12000000e+00, 9.08000000e+00, ...,
4.41000000e+02, 8.33490000e+03, 1.57529610e+05],
...,
[1.00000000e+00, 4.97000000e+00, 3.26000000e+00, ...,
4.08040000e+02, 7.58550400e+03, 1.41015270e+05],
[1.00000000e+00, 6.17400000e+00, 2.41600000e+01, ...,
4.49440000e+02, 8.22729600e+03, 1.50606086e+05],
[1.00000000e+00, 6.19300000e+00, 2.15200000e+01, ...,
4.08040000e+02, 1.95394600e+03, 9.35669290e+03]])
X_train_poly
Out[0]
array([[1.00000000e+00, 6.22300000e+00, 2.17800000e+01, ...,
4.08040000e+02, 7.95354800e+03, 1.55031188e+05],
[1.00000000e+00, 6.12200000e+00, 5.98000000e+00, ...,
3.38560000e+02, 7.30296000e+03, 1.57529610e+05],
[1.00000000e+00, 6.94300000e+00, 4.59000000e+00, ...,
2.16090000e+02, 5.34242100e+03, 1.32081365e+05],
...,
[1.00000000e+00, 5.70800000e+00, 1.17400000e+01, ...,
3.84160000e+02, 7.66614800e+03, 1.52982677e+05],
[1.00000000e+00, 7.82000000e+00, 3.76000000e+00, ...,
2.22010000e+02, 5.77091900e+03, 1.50009036e+05],
[1.00000000e+00, 5.63100000e+00, 2.99300000e+01, ...,
2.31040000e+02, 5.87677600e+03, 1.49482757e+05]])
モデル作成
import numpy as np from sklearn.linear_model import LinearRegression model = LinearRegression() model.fit(X_train_poly,Y_train)
Out[0]
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
精度確認
# 自由度調整済みr2を算出 def adjusted_r2(X,Y,model): from sklearn.metrics import r2_score import numpy as np r_squared = r2_score(Y, model.predict(X)) adjusted_r2 = 1 - (1-r_squared)*(len(Y)-1)/(len(Y)-X.shape[1]-1) #yhat = model.predict(X) \ #SS_Residual = sum((Y-yhat)**2) \ #SS_Total = sum((Y-np.mean(Y))**2) #r_squared = 1 - (float(SS_Residual))/ SS_Total return adjusted_r2 # 予測モデルの精度確認の各種指標を算出 def get_model_evaluations(X_train,Y_train,X_test,Y_test,model): from sklearn.metrics import explained_variance_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error from sklearn.metrics import mean_squared_log_error from sklearn.metrics import median_absolute_error # 評価指標確認 # 参考: https://funatsu-lab.github.io/open-course-ware/basic-theory/accuracy-index/ yhat_test = model.predict(X_test) return "adjusted_r2(train) :" + str(adjusted_r2(X_train,Y_train,model)) \ , "adjusted_r2(test) :" + str(adjusted_r2(X_test,Y_test,model)) \ , "平均誤差率(test) :" + str(np.mean(abs(Y_test / yhat_test - 1))) \ , "MAE(test) :" + str(mean_absolute_error(Y_test, yhat_test)) \ , "MedianAE(test) :" + str(median_absolute_error(Y_test, yhat_test)) \ , "RMSE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test))) \ , "RMSE(test) / MAE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test)) / mean_absolute_error(Y_test, yhat_test)) #better if result = 1.253
get_model_evaluations(X_train_poly,Y_train,X_test_poly,Y_test,model)
Out[0]
('adjusted_r2(train) :0.7867047581708189',
'adjusted_r2(test) :0.808718224430905',
'平均誤差率(test) :0.13584897181860284',
'MAE(test) :2.647648209255964',
'MedianAE(test) :2.037836832438849',
'RMSE(test) :3.9642820168433515',
'RMSE(test) / MAE(test) :1.497284270238222')
MAEで確認すると2,648ドル誤差がある。重回帰よりかなり精度が向上した。 平均誤差率も13.6%と低めになった。
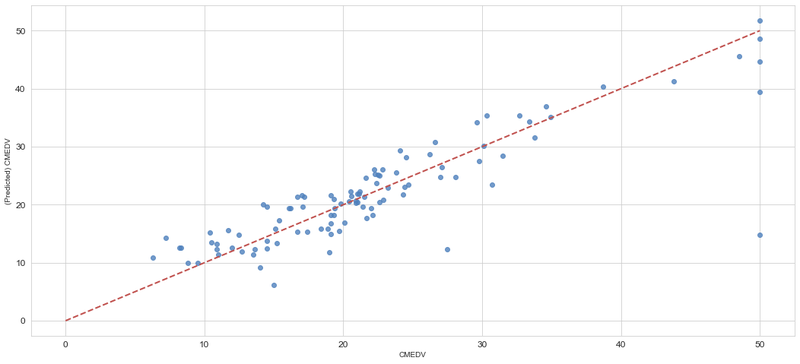
# 描画設定 from matplotlib import rcParams rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch) import matplotlib.pyplot as plt from matplotlib import ticker sns.set_style("whitegrid") # seabornのスタイルセットの一つ sns.set_color_codes() # デフォルトカラー設定 (deepになってる) plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test_poly), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]

いまさらですが、上記図の説明です。横に実際の販売価格。縦に予測した販売価格の値をプロットした図です。赤い点線に近いほど、実測と予測の誤差が少ない事を表しています。2つの住宅が大きく予測を外れているようです。原因を究明して除外したいところです。
n=3で試してみる
import numpy as np from sklearn.linear_model import LinearRegression from sklearn.preprocessing import PolynomialFeatures poly_reg = PolynomialFeatures(degree = 3) X_train_poly = poly_reg.fit_transform(X_train) X_test_poly = poly_reg.fit_transform(X_test) model = LinearRegression() model.fit(X_train_poly,Y_train)
Out[0]
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False)
get_model_evaluations(X_train_poly,Y_train,X_test_poly,Y_test,model)
Out[0]
('adjusted_r2(train) :0.8106797309010914',
'adjusted_r2(test) :0.6031191488726811',
'平均誤差率(test) :0.17954728252488114',
'MAE(test) :3.097778694543558',
'MedianAE(test) :2.361241934901205',
'RMSE(test) :5.00242469939101',
'RMSE(test) / MAE(test) :1.6148425025332844')
n=2の方が精度がよい。訓練データでのR2とテストデータのR2を比べると差があるので、 若干オーバーフィットしているのではないかと思われる。
# 描画設定 from matplotlib import rcParams rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch) import matplotlib.pyplot as plt from matplotlib import ticker sns.set_style("whitegrid") # seabornのスタイルセットの一つ sns.set_color_codes() # デフォルトカラー設定 (deepになってる) plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test_poly), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]
n=2よりは当てはまりが良くなさそうですね