その5 ボストンの住宅価格をサポートベクター回帰(SVR)で予測してみた
いつものボストン住宅価格の予測モデル作成です。
今回はサポートベクター回帰というものを 使ってみました。
サポートベクターマシーン(SVM)という名前は分類問題で よく聞きましたが、SVMの概念を回帰に適用したものをサポートベクター回帰(Support Vector Regression)と呼ぶそうです。
SVMが他のアルゴリズムと差別化される特徴は、ただいくつかの点を分離する超平面を捜すことで終わるのではなく、いくつかの点を分離することができる幾多の候補平面の中でマージンが最大になる超平面 (maximum-margin hyperplane) を探す点にある。 参照: https://ja.wikipedia.org/wiki/サポートベクターマシーン
SVMのイメージは下記

出展:https://en.wikipedia.org/wiki/File:Svm_separating_hyperplanes_(SVG).svg
.svg){kind=link}
H1でもH2でもなく、H3のように分類できると新しいデータが 黒い点に近いほうに存在する場合は黒に分類され、白い点に近い(赤い線の右側のエリア)に存在する場合は白に分類されるようになる。
それではSVRモデル作成してみます。
Checking Boston housing prices corrected dataset 5
パッケージのインポート
import packages
import seaborn as sns import statsmodels.api as sm import pandas as pd
データの読み込み
reading data
df = pd.read_csv("http://lib.stat.cmu.edu/datasets/boston_corrected.txt",skiprows=9,sep="\t")
※ 22年2月1日更新: UnicodeDecodeErrorが発生する方はencoding='Windows-1252'を追加してください。 詳細は下記新ブログをご参照ください。
list(df.columns)
Out[0]
['OBS.',
'TOWN',
'TOWN#',
'TRACT',
'LON',
'LAT',
'MEDV',
'CMEDV',
'CRIM',
'ZN',
'INDUS',
'CHAS',
'NOX',
'RM',
'AGE',
'DIS',
'RAD',
'TAX',
'PTRATIO',
'B',
'LSTAT']
モデリング
SVRを試す
サンプリング (訓練データ、テストデータ分割)
# 訓練データとテストデータに分割する。 # 本当は町ごとにサンプリングした方がいいと思うが、TODOにしておく。 from sklearn.model_selection import train_test_split # TODO:層別サンプリング train, test = train_test_split(df, test_size=0.20, stratify=df["町区分"], random_state=100) train, test = train_test_split(df, test_size=0.20,random_state=100)
訓練データ、テストデータ作成
# 変数の組み合わせは前回の重回帰分析と同じ X_train = train[["RM","LSTAT","PTRATIO","B"]] Y_train = train["CMEDV"] X_test = test[["RM","LSTAT","PTRATIO","B"]] Y_test = test["CMEDV"]
モデル作成
import numpy as np from sklearn.svm import SVR model = SVR(kernel='rbf', C=1e3, gamma='scale') model.fit(X_train,Y_train)
Out[0]
SVR(C=1000.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale',
kernel='rbf', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
精度確認
# 自由度調整済みr2を算出 def adjusted_r2(X,Y,model): from sklearn.metrics import r2_score import numpy as np r_squared = r2_score(Y, model.predict(X)) adjusted_r2 = 1 - (1-r_squared)*(len(Y)-1)/(len(Y)-X.shape[1]-1) #yhat = model.predict(X) \ #SS_Residual = sum((Y-yhat)**2) \ #SS_Total = sum((Y-np.mean(Y))**2) #r_squared = 1 - (float(SS_Residual))/ SS_Total return adjusted_r2 # 予測モデルの精度確認の各種指標を算出 def get_model_evaluations(X_train,Y_train,X_test,Y_test,model): from sklearn.metrics import explained_variance_score from sklearn.metrics import mean_absolute_error from sklearn.metrics import mean_squared_error from sklearn.metrics import mean_squared_log_error from sklearn.metrics import median_absolute_error # 評価指標確認 # 参考: https://funatsu-lab.github.io/open-course-ware/basic-theory/accuracy-index/ yhat_test = model.predict(X_test) return "adjusted_r2(train) :" + str(adjusted_r2(X_train,Y_train,model)) \ , "adjusted_r2(test) :" + str(adjusted_r2(X_test,Y_test,model)) \ , "平均誤差率(test) :" + str(np.mean(abs(Y_test / yhat_test - 1))) \ , "MAE(test) :" + str(mean_absolute_error(Y_test, yhat_test)) \ , "MedianAE(test) :" + str(median_absolute_error(Y_test, yhat_test)) \ , "RMSE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test))) \ , "RMSE(test) / MAE(test) :" + str(np.sqrt(mean_squared_error(Y_test, yhat_test)) / mean_absolute_error(Y_test, yhat_test)) #better if result = 1.253
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
Out[0]
('adjusted_r2(train) :0.6328496989408552',
'adjusted_r2(test) :0.6318780385281525',
'平均誤差率(test) :0.1739854525137672',
'MAE(test) :3.7604132658307456',
'MedianAE(test) :2.355126673770974',
'RMSE(test) :5.840637471080945',
'RMSE(test) / MAE(test) :1.5531903166474548')
結果は、、、うーんって感じですね。パラメータチューニングがうまくいくともっと精度があがると思うのですが私がまだまだ使いこなせてないです。
ニューラルネットワークと同じ道を辿ってしまいました。
現状一番精度がよいモデルは多項式回帰ですね。
多項式回帰の結果
'adjusted_r2(train) :0.7867047581708189' 'adjusted_r2(test) :0.808718224430905' '平均誤差率(test) :0.13584897181860284' 'MAE(test) :2.647648209255964'
平均誤差率10%台を目指したいですね。
# 描画設定 from matplotlib import rcParams rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch) import matplotlib.pyplot as plt from matplotlib import ticker sns.set_style("whitegrid") # seabornのスタイルセットの一つ sns.set_color_codes() # デフォルトカラー設定 (deepになってる) plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]

import numpy as np from sklearn.svm import SVR model = SVR(kernel='poly', C=1e3, gamma='scale') model.fit(X_train,Y_train)
Out[0]
SVR(C=1000.0, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale',
kernel='poly', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
Out[0]
('adjusted_r2(train) :0.6623761093367708',
'adjusted_r2(test) :0.6648867826467878',
'平均誤差率(test) :0.16663659609727666',
'MAE(test) :3.486887354769383',
'MedianAE(test) :2.4425100356405203',
'RMSE(test) :5.572629444815989',
'RMSE(test) / MAE(test) :1.5981673274284922')
plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]
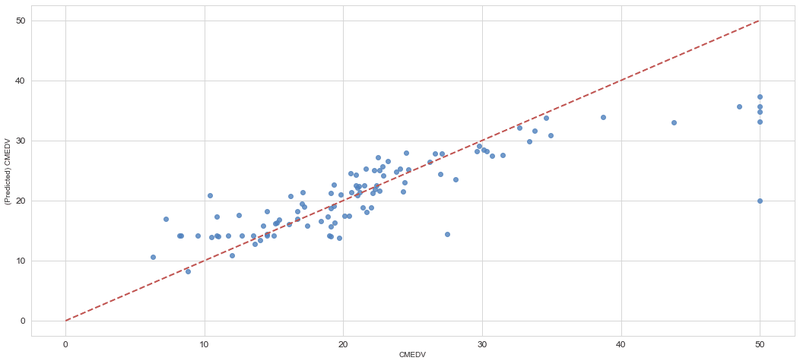
import numpy as np from sklearn.svm import SVR model = SVR(kernel='linear', C=10,gamma='scale') model.fit(X_train,Y_train)
Out[0]
SVR(C=10, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale',
kernel='linear', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
Out[0]
('adjusted_r2(train) :0.662129101394711',
'adjusted_r2(test) :0.6920616469466916',
'平均誤差率(test) :0.20877267777002476',
'MAE(test) :3.3318066638504322',
'MedianAE(test) :2.3721543497060313',
'RMSE(test) :5.341906448016301',
'RMSE(test) / MAE(test) :1.6033062500219863')
plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")

import numpy as np from sklearn.svm import SVR model = SVR(kernel='sigmoid', C=1,gamma='scale') model.fit(X_train,Y_train)
Out[0]
SVR(C=1, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale',
kernel='sigmoid', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
Out[0]
('adjusted_r2(train) :0.04206986292158499',
'adjusted_r2(test) :0.05265190714913759',
'平均誤差率(test) :0.30139535856381794',
'MAE(test) :6.3358301165840905',
'MedianAE(test) :4.535610833151454',
'RMSE(test) :9.369559624608875',
'RMSE(test) / MAE(test) :1.478821157165179')
plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]

全変数投入で試してみる
FEATURE_COLS=[ #'OBS.', #'TOWN', #'TOWN#', #'TRACT', #'LON', #'LAT', #'MEDV', #'CMEDV', 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT'] X_train = train[FEATURE_COLS] Y_train = train["CMEDV"] X_test = test[FEATURE_COLS] Y_test = test["CMEDV"]
import numpy as np from sklearn.svm import SVR model = SVR(kernel='linear', C=10,gamma='scale') model.fit(X_train,Y_train)
Out[0]
SVR(C=10, cache_size=200, coef0=0.0, degree=3, epsilon=0.1, gamma='scale',
kernel='linear', max_iter=-1, shrinking=True, tol=0.001, verbose=False)
get_model_evaluations(X_train,Y_train,X_test,Y_test,model)
Out[0]
('adjusted_r2(train) :0.688568508382418',
'adjusted_r2(test) :0.6797804532984677',
'平均誤差率(test) :0.18938285727794626',
'MAE(test) :3.145649647478316',
'MedianAE(test) :2.164607242122292',
'RMSE(test) :5.188523341327783',
'RMSE(test) / MAE(test) :1.6494282335247092')
# 描画設定 from matplotlib import rcParams rcParams['xtick.labelsize'] = 12 # x軸のラベルのフォントサイズ rcParams['ytick.labelsize'] = 12 # y軸のラベルのフォントサイズ rcParams['figure.figsize'] = 18,8 # 画像サイズの変更(inch) import matplotlib.pyplot as plt from matplotlib import ticker sns.set_style("whitegrid") # seabornのスタイルセットの一つ sns.set_color_codes() # デフォルトカラー設定 (deepになってる) plt.figure() ax = sns.regplot(x=Y_test, y=model.predict(X_test), fit_reg=False,color='#4F81BD') ax.set_xlabel(u"CMEDV") ax.set_ylabel(u"(Predicted) CMEDV") ax.get_xaxis().set_major_formatter(ticker.FuncFormatter(lambda x, p: format(int(x), ','))) ax.get_yaxis().set_major_formatter(ticker.FuncFormatter(lambda y, p: format(int(y), ','))) ax.plot([0,10,20,30,40,50],[0,10,20,30,40,50], linewidth=2, color="#C0504D",ls="--")
Out[0]
